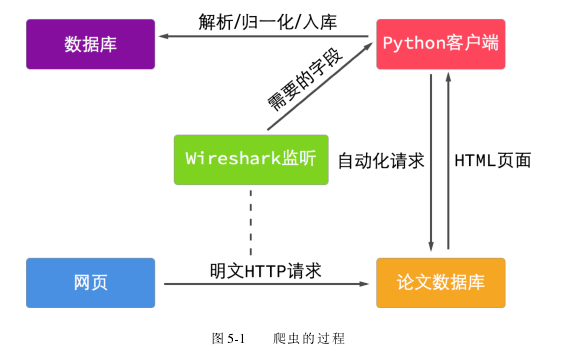
文数据库并没有提供公开的 API, 所以先人工在网页界面检索和下载论文, 同时使用 Wireshark 工具对 HTTP 流量进行抓包。通过对抓取的数据包进行分析和比对, 可以得到自动抓取所需要的字段。接下来, 使用 Python 编写一个 HTTP 协议客户端, 模拟界面点击操作, 将分析出的字段发送给论文服务器, 即可得到想要访问的页面。服务器返回的数据一般为 HTML 页面, 为了提取出我们想要的信息, 需要对这种格式化的数据进行解析。由于 HTML 页面的编码符合 XML 标准, 所以最终选用可以解析 XML 格式数据的 Beautiful Soup 库对页面进行分析。通过浏览器的开发者工具, 可以看到网页的源代码, 找出目标字段所在 HTML 标签的特有信息, 比如样式、属性或者路径, 就能够通过 Beautiful Soup 库提供的函数对其进行搜索,该过程如图5-1所示。
..........


